Видео с ютуба Deepseek V4 Attention

The End of Standard Attention in LLMs? | DeepSeek-V4 Paper Explained
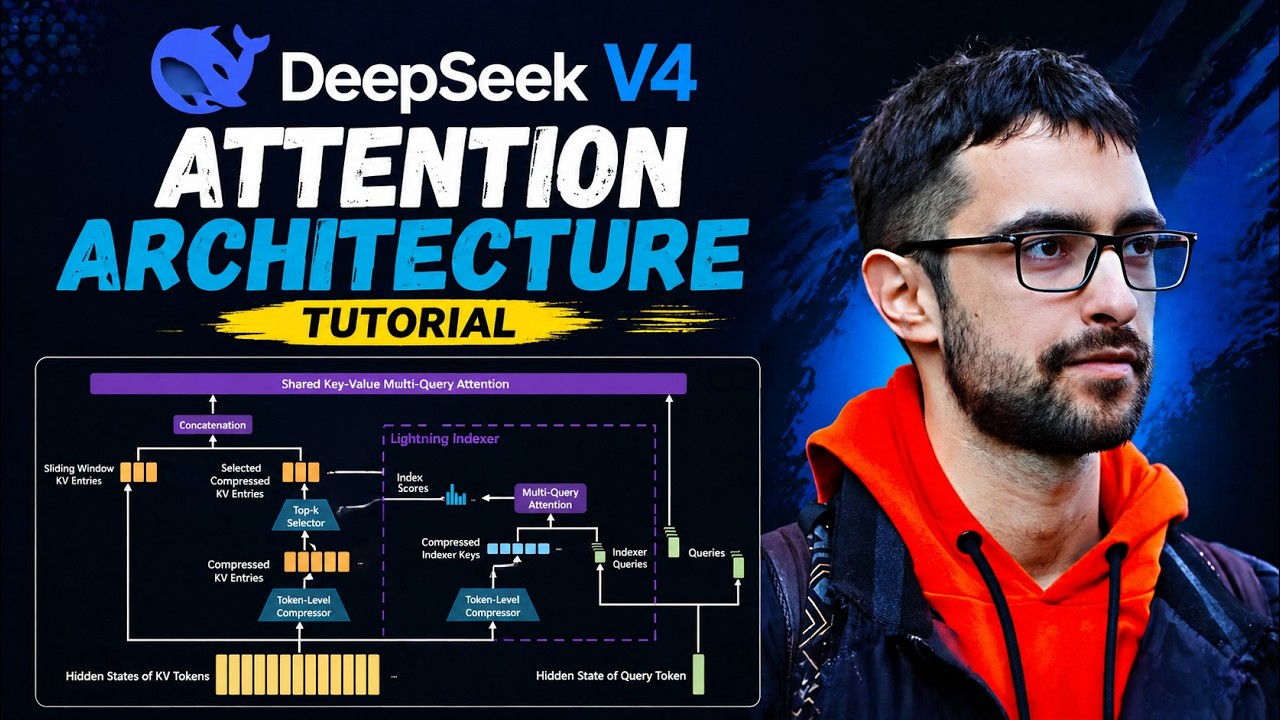
DeepSeek V4 Attention Architecture - Tutorial
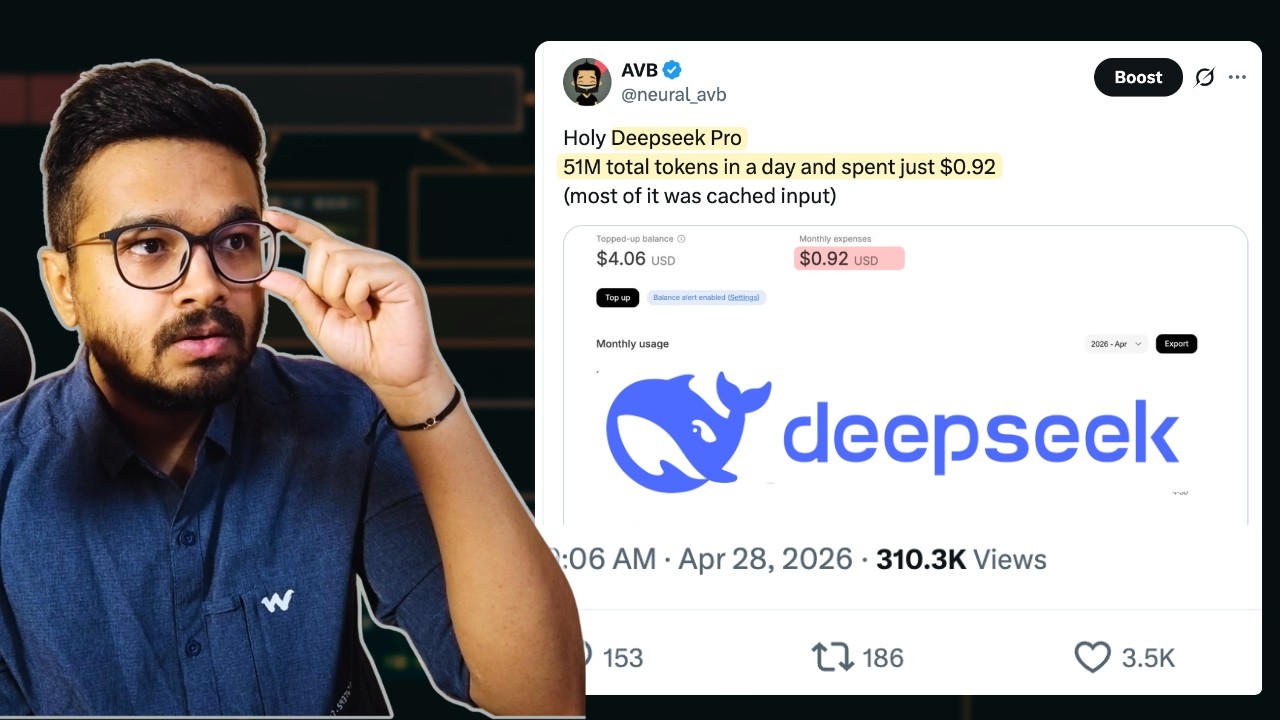
DeepSeek V4 настолько мощный, но почему он такой ДЕШЕВЫЙ? (Подробный анализ механизма Sparse Atte...

FlashMemory-DeepSeek-V4: Lightning Index Ultra-Long Context via Lookahead Sparse Attention (июнь ...

Секрет DeepSeek V4: на 98% меньше памяти.

DeepSeek v4 The Scaling Wall Pro
![How DeepSeek Rewrote the Transformer [MLA]](https://imager.clipsaver.ru/0VLAoVGf_74/max.jpg)
How DeepSeek Rewrote the Transformer [MLA]

Объяснение принципа разреженного внимания DeepSeek: на 80% дешевле ИИ с длинным контекстом

DeepSeek V4 навсегда изменил ИИ — подробный технический анализ CSA, HCA, mHC, Muon, OPD

My Honest Thoughts about Deepseek

Lookahead Sparse Attention: cut the KV cache to 13.5% (FlashMemory / DeepSeek-V4)

Анализ DeepSeek V4..

DeepSeek v4 за 4 минуты
![[Video Special] DeepSeek-V4 Architecture and KV Cache Optimization](https://imager.clipsaver.ru/rvLL8tQl4hg/max.jpg)
[Video Special] DeepSeek-V4 Architecture and KV Cache Optimization

DeepSeek-V4: объяснение принципа работы гибридной архитектуры CSA и HCA, снижающей кэш ключ-значе...

Why DeepSeek V4 Impresses Despite Lack of 'Wow' Factor

1M Context in 500MB?! DeepSeek V4 + TurboQuant Explained

Deepseek v4: практическое применение в контексте 1 миллиона токенов.

DeepSeek-V4: Efficient Million-Token Context Intelligence

Deepseek v4 attention deep dive: how it handles 1M context